

IP9: Could a scarcity of data be a roadblock to AI Progress?
IP9: Could a scarcity of data be a roadblock to AI Progress?
Scarcity of high quality data, along with privacy, copyright and geopolitics could act as bottlenecks to progress

I hope everyone had a lovely Easter weekend. I had the joy of spending it in the delightful Northumbrian countryside And thanks to the folks I spoke to in the North East, who’ve signed up to this Substack.
I appreciate all of the feedback on the Substack so far. Please drop me a line david@artemonstrategy.com if you have any thoughts or suggestions.
You can read more about Artemon at our website here.
If you like this newsletter, do please subscribe and share. And please click the ♡symbol at the top of the post - Substack’s algorithms love the like symbol.
A quick “parish notice” - there won’t be a Substack next weekend as I’ll be a part of Yorkshire with “erratic” connectivity. Back in a fortnight though.
Should we be worried about data scarcity being a roadblock to AI progress?
As we’ve discussed in pretty much every Inflection Points, AI means that tech itself is at an inflection point. The ongoing advance of Artificial Intelligence has the potential to transform every industry and drive incredible advances in fields ranging from healthcare to agriculture to manufacturing.
The remarkable advances seen so far have been based on three factors, as described by Open AI (the brains behind Chat GPT):
“algorithmic innovation, data (which can be either supervised data or interactive environments), and the amount of compute available for training.”
We can be confident that algorithmic innovation will continue. There is a separate discussion about the increasing cost of compute as large language models grow in size.
But what about the availability of training data for large language models? Is there a guarantee that we can access the good quality data that AI needs to advance? And what might this mean for companies who are relying on AI to transform their operations? At the very least, do we need to consider an AI data scarcity as part of emerging scenarios?
As part of this discussion, we need to consider whether there is a potential for a shortage of training data that is high quality; legally available; not privacy intrusive; and geographically diverse. Could roadblocks to AI progress emerge from scarcity of high quality training data; copyright interventions from rights owners; privacy interventions from regulators; and “sovereignty” based interventions from nation states. There’s another conversation to be had about diversity and fairness. But that’s a discussion for another day.
Might we run out of high quality training data? Could data scarcity be a roadblock to AI progress?
The large language models that have been developed so far have, as the name implies, been built on large “training sets” of available data. As researchers at Cornell University suggest, current “understanding of scaling laws suggests that future ML capabilities will strongly depend on the availability of large amounts of data to train large models.”
These models have so far been trained more on higher quality data, such as scientific journals, news articles, books, Wikipedia and filtered web content rather than user-generated content, which has proliferated in recent years. High quality data is regarded as having passed “usefulness filters”, such as peer review or an editing process.
As such, large language models trained on high quality data tend to perform much better than those having to rely on lower quality data. Lower quality training data can introduce “noise” into the dataset, promote spurious correlations and lead to data bias. Researchers argue that:
“around half of the improvement in language models over the past four years comes from training them on more data. Without further room to scale datasets, this [a shortage of high quality data] would lead to a slowdown in AI progress.”
But high quality data is, by its very nature, scarcer than lower quality data.
These researchers then considered what historical growth of datasets for training data would mean for data availability to power AI in the future. They “estimated the limit of these trends due to the exhaustion of available data.” This led to a potentially alarming conclusion that:
“Data stocks grow at a much slower pace than dataset sizes, so if current trends continue, datasets will eventually stop growing due to data exhaustion. Our models show this is likely to happen between 2030 and 2040 for language data, and between 2030 and 2060 for vision data. … If our assumptions are correct, data will become the main bottleneck for scaling ML models, and we might see a slowdown in AI progress as a result… the high-quality language stock will almost surely be exhausted before 2027 if current trends continue.”
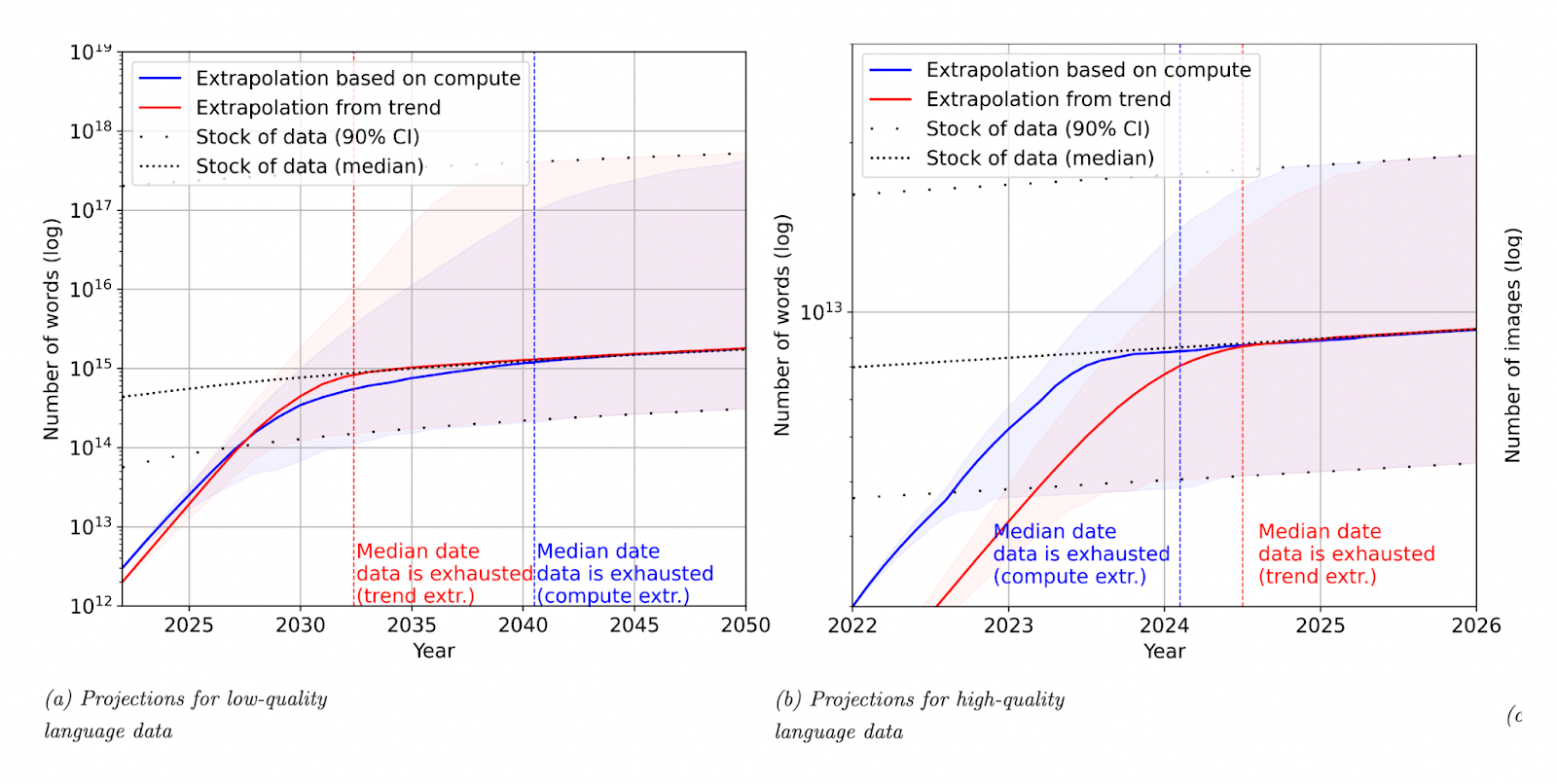
Generative AI is, after all, not necessarily going to increase the number of scientific papers, the quality of news articles or the level of R & D in an economy in a way that will ensure that high quality data sources also increase. On the flip side, there is a risk that the quantity of information on the internet will massively increase and this flood could be disproportionately be of poor quality data.
Scarcity of high-quality data acting as a roadblock to AI’s advance is not inevitable. As many have pointed out, generative AI itself and notably synthetic data might help to solve the problem. Heuristics and transfer learning might also be important and models might evolve in a way in which requires less data. The formative paper for LLMs - “Attention Is All You Need” placed importance on the evolution of transformers, networks and relationships, rather than the data itself. Governments and the private sector might also increase R&D investment in a way that increases the amount of high quality data.
Despite this, we shouldn’t rule out the possibility that scarcity of high quality data will prove a roadblock to AI’s advance. And, as per Inflection Points 6, boards should consider this as they develop an AI strategy.
Could there be a scarcity of legal and available data? Might copyright issues be a roadblock to generative AI?
The past few waves of the internet have seen the web and tech companies having to adjust to the demands of copyright and intellectual property. In the early days of the internet, Napster transformed the way many people consumed music before running into understandable legal issues from music publishers. Streaming eventually transformed music publishing anyway, so that streaming now represents 84% of music industry revenue in the US. Similarly, social media and YouTube had to adjust to the concerns of copyright holders. They have largely come to agreements with copyright holders to tackle copyright violation, meaning that YouTube is increasingly important not just as a means of watching video but as a means of watching TV.
It seems inevitable that generative AI will run into similar issues. But it runs into the additional challenge that AI will potentially allow people to potentially pass off work as their own, without the need for citations or accreditation. HBR put it neatly when they said that:
This process comes with legal risks, including intellectual property infringement. In many cases, it also poses legal questions that are still being resolved. For example, does copyright, patent, trademark infringement apply to AI creations? Is it clear who owns the content that generative AI platforms create for you, or your customers? Before businesses can embrace the benefits of generative AI, they need to understand the risks — and how to protect themselves.
A pertinent case is already happening amongst news publishers. Some news organisations are already beginning to experiment with utilising AI within news production, but others are concerned that generative AI is using news stories without sufficient attribution. The INMA suggest that the likes of ChatGPT “raises important issues about sourcing, trust, payment to content creators, or even recognition that they exist, as well as future sources of revenue.”
Open AI argue that the “scraping” of news sites constitutes “fair use”. Others, however, argue that issues are raised around “the lack of compensation (or even attribution) for publishers” The likes of Barry Dillier are already comparing this moment with the early days of the internet and pushing publishers to take decisive legal steps.
It seems probable that both generative AI and copyright holders will adapt to the emerging environment. But we cannot rule out some kind of impasse acting as a block on further development of generative AI.
Could there be a scarcity of non-intrusive data? Might privacy issues be a roadblock to generative AI?
The use of sensors heralds a field of training data that is likely to increase in the next few years. One report suggest that the AI related sensor market will be likely to see at 40% and other market analysis suggests “dramatic advances” in the use of sensors and similar across devices.
There are already up to twenty sensors in the average smartphone, including sensors ranging from a pedometer to a proximity sensor.

This number is only likely to increase over time. Other items that we use in our everyday life are likely to be more reliant on sensors to improve user experience and improve the devices. This will both increase the usefulness of these devices over time and provide invaluable training data for language models. But will this lead to privacy concerns about intrusiveness and will this lead to regulation limiting the use of such data of large language models?
The same concern might apply to data protection issues around emails etc. As Casey Newton and Kevin Roose discussed on their Hard Fork podcast recently, generative AI could have a thoroughly transformative impact if linking together aspects of someone’s online existence - using emails, search, meeting notes etc to personalise generative AI in a highly powerful and integrated way. AI could potentially lead to “hyper personalisation”, with generative AI acting as an efficient and knowledgeable assistant in every aspect of life. Spotify’s AI DJ is possibly the best recent example of how AI could be used to enhance personalisation.
Such a shift that would bring benefits would also come with privacy concerns. Hyper personalisation be a labour saving utopia for many, but others might set the privacy and data protection alarm. As an excellent recent piece by Eileen Guo and Tate Ryan-Mosley suggested:
All technology users face similar questions about how and where to draw a personal line when it comes to privacy. But outside of our own homes (and sometimes within them), we increasingly lack autonomy over these decisions. Instead, our privacy is determined by the choices of the people around us. Walking into a friend’s house, a retail store, or just down a public street leaves us open to many different types of surveillance over which we have little control.
Italy, for example, has already proscribed Chat GPT for privacy reasons. Given the focus of regulators in many jurisdictions on privacy, there is also the potential that regulatory roadblocks might get in the way of AI achieving maximum usefulness.
If the debate pivots more towards protection and against usefulness, might this also potentially stunt the growth in usefulness of AI models?
Could there be a scarcity of data that isn’t American? Might geopolitics be a roadblock to AI progress?
If most of the AI training data is developed by data scientists based in America, using largely American data, does that mean that the AI outputs with have an American tilt. This was a question posed in an excellent MIT article by Melissa Heikilla recently:
These models are built by American companies and trained on North American data, and thus when they’re asked to generate even mundane everyday items, from doors to houses, they create objects that look American, Federico Bianchi, a researcher at Stanford University, tells me… As the world becomes increasingly filled with AI-generated imagery, we are going to mostly see images that reflect America’s biases, culture, and values. Who knew AI could end up being a major instrument of American soft power?
This is, of course, not inevitable. Deepmind is based in London and has produced the most cited AI papers for the past two years. Nevertheless, as the chart below shows, outside of China the great bulk of cited papers on AI have been from the United States.
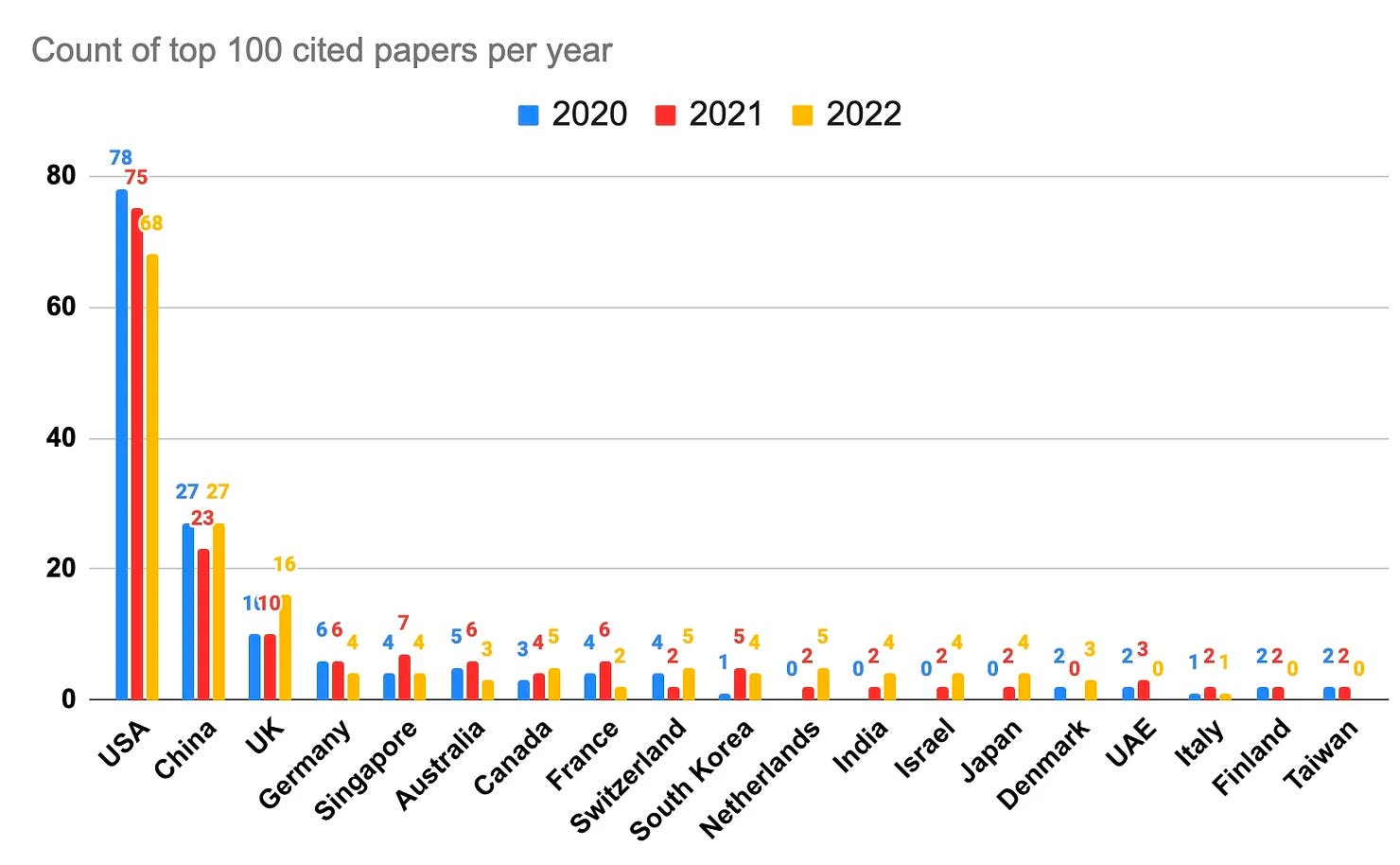
Although slightly dated, the chart below also illustrates that the bulk of AI companies are based in the United States:
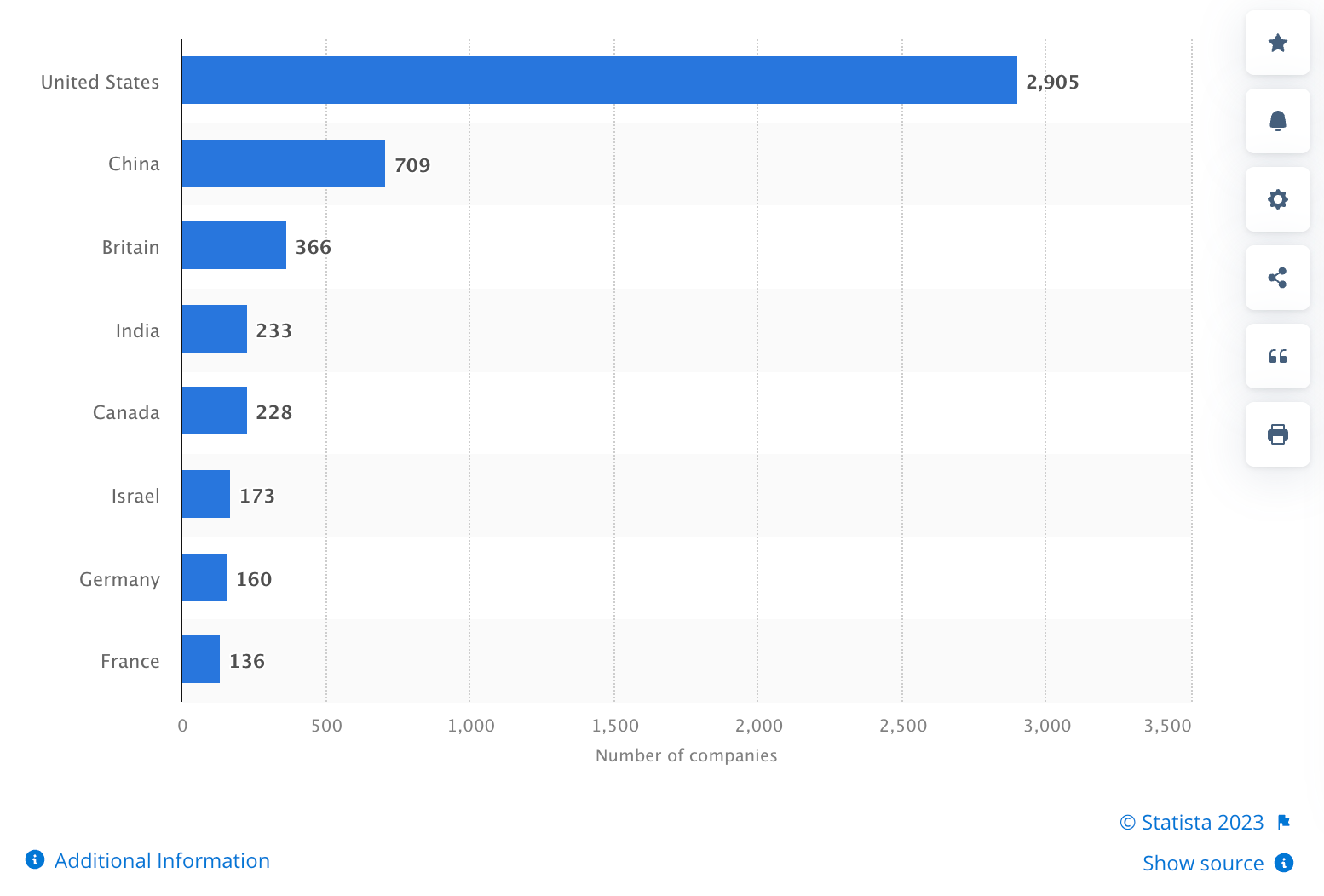
A narrowness of training data could accentuate issues that already exist around techno-nationalism, with leaders ranging from Modi to Macron pudding back against a perception of American tech hegemony. An AI that largely utilises American data could entrench American dominance of tech, but it could also accelerate the push back against this perceived dominance.
Getting to grips with geopolitical uncertainty
Artemon is founded on the concept that companies need foresight capabilities to handle unprecedented levels of uncertainty. This World Economic Forum report is an interesting primer about the importance that leaders are giving towards understanding geopolitical instability.
This geopolitical uncertainty is creating new demands on C-suite and on management, but it’s also increasing demands on corporate boards. As The Economist put it in an interesting read, boards are now “expected to help bosses navigate war, geopolitical strife, the return of high inflation, climate change and technological disruption, all in the aftermath of a once-in-a-century pandemic.”
A fascinating discussion, involving Google, Intel and Pfizer, and chaired by McKinsey’s Ziad Haider, considers how companies need to navigate geopolitical risk to build resilience. Geopolitical risk “is center stage. There are the Russia–Ukraine conflict, strenuous relationships among countries across the globe, internet restrictions, and competing interests across Europe. The conflicts themselves are hard enough, but disinformation is another element making it even tougher for companies and organizations to navigate risk successfully.”
And Finally
Some worthwhile nuggets from the past week:
Apple are in talks to manufacture Macbooks in Thailand. Another shift towards “friendshoring”?
Why network effects mean that big tech platforms aren’t easily replaced.
The potential for the Indian government to gain the power to fact-check and delete social media posts.
Japan has approved its first ever casino.